
M Y S C I E N C E
My intellectual interests vary widely, typically driven by hard real-world problems I have encountered.
My time at Courant was spent pondering whether Mathematical Logic was really my intellectual pursuit. Nope, it wasn’t. I got hooked on Artificial Intelligence and Machine Learning, at the time a nascent field of study still focused on Inductive Inference. My thesis research question was suspiciously simple: how might one teach a machine to solve jigsaw puzzles quickly without relying upon blind search? I focused on training a learning machine by solving many children’s puzzles (thank you Sesame Street’s Count von Count) so the system would learn “problem-solving heuristics” represented in a language that describes sequences of tokens or events. I had cast the problem formally as learning a regular expression language given a set of words in the language, each word was a sequence of puzzle moves that were used in solving an instance of a puzzle. I was thrilled to have proved the problem of learning the minimum length regular expression consistent with a set of training examples was NP-complete. This was quickly followed by deep despair when a fellow student came into my office to show me Dana Angluin’s proof of same published just a few weeks earlier. Being scooped is no fun.
When I appeared at Columbia soon after my graduation, I became focused on the pursuit to develop efficient algorithms and systems to learn from large amounts of data and solve hard problems. This theme largely served as a guide for most of the work I’ve pursued. But I am a bit different than many others. My intellectual interests vary widely, typically driven by hard real-world problems I have encountered that simply capture my attention.
Over the years, I’ve worked on Mathematical Logic and resolution theorem-proving, AI rule-based systems, parallel computing, large-scale data analytics, and ultimately found my way into cybersecurity, which has largely consumed my time and energy over the past couple of decades. Even within the security research field, I have been attracted to problems in network security where my ideas of applying machine learning to network trace data are now commonplace.

_______
Perhaps another theme in my work, especially in my consulting work for government, is “you have to learn how to break it in order to fix it”.
Together with students from my lab and colleagues, I’ve also researched host security and anomaly detection, user behavior analytics, even hardware security, especially the embedded devices that are so easily attacked.
As many professors will recall, salaries in the 1970’s and 80’s forced young assistant professors to collaborate and consult with industry if one enjoyed eating. Thank you Bell Labs and Citibank. Here was my first entree into automatic analysis of large amounts of real-world data. What follows is a chronological evolution of the problems that have motivated my research and have hopefully led to (discernible) real world impact.
1. ACE: THE FIRST DEDUCTIVE DATABASE SYSTEM AND APPLICATION
Among my earliest work, along with colleague Greg Vesonder of Bell Labs, we developed a large-scale expert data analysis system, called ACE (Automated Cable Expertise) for the nation's phone system. AT&T Bell Labs distributed ACE to a number of telephone wire centers to improve the management and scheduling of repairs in the local loop. ACE is likely to have been the first system to combine rule-based inference (an AI expert system) with a relational database management system, the AT&T CRAS system, and serves as a model for deductive database systems that were the subject matter of research for many years in the database community. ACE was the first expert system of its kind that was commercialized and widely distributed. I unfortunately had no carry on that deal. More consulting was needed.

AT&T’s ACE Brochure.
2. MERGE/PURGE, DE-DUPLICATION OF LARGE DATASETS
While I was a consultant for Citibank, I learned a hard lesson about the “real-world data” companies were confronted with: “It’s dirty”. To compute any effective statistical model of data or accurately extract useful knowledge from a very large database, input records merged across multiple sources are often duplicative, although they are not perfectly equivalent. I may appear as Sal in one database, and Salvo in another. Both records should be replaced by just one. This “post office problem” is familiar to many. In the large commercial enterprises in general it is called “de-duplication” or the "merge/purge" problem. An algorithm developed with student Mauricio Hernandez has been used in large-scale commercial systems for data cleansing. Identifying and purging duplicates from large data sets is a very important part of large-scale data analysis systems, especially in commercial data analytics.
I also extended the idea of "de-duplication" to check image processing. Writing checks, which are imaged and stored by your bank, is an exercise in duplicating most of the image data, the background of each check occupies more pixels than the variable content, the handwriting on the check. I conceived of a check image compression technique that was patented (see US patents 5,668,897 and 5,748,780.) and licensed to a third party. If you use a bank app on your phone and deposit checks, you will see no background on the confirmation email of the check. You are welcome.
3. IMPROVED CREDIT CARD FRAUD DETECTION AND THE JAM PROJECT
Probably the most intellectually interesting problem I discovered while consulting for Citibank for several years was fraud. Good old fashioned fraud conducted by credit card thieves. I had been pursuing research on deductive inference and machine learning algorithms applied to the large datasets, and the credit card fraud problem dropped into my lap as a perfect example. Much of that work with students Phil Chan (now at Florida Tech) and Andreas Prodromidis was published as "meta-learning"- based strategies, demonstrating how to improve the accuracy of fraud detectors and substantially reduce loss. This work is among the first examples of privacy- preserving, distributed data mining. We developed the JAM project (Java Agents for Meta-Learning), a sophisticated machine learning infrastructure that I’m sure has been replicated by many for their own internal use.

The real world provides so many interesting problems, many based upon one or another constraint to be overcome in order to compute a solution to a problem. Processing large amounts of data was simply expensive, especially for computing pattern matching algorithms over large number of samples drawn from some environment. I became quite interested in the exploding research in VLSI systems and parallel computing, perhaps an obvious means of scaling AI algorithms to large databases, so I thought.
4. DADO PARALLEL COMPUTER
Along with students Dan Miranker (now at UT Austin), Michael van Biema, Alexander Pasik (now deceased) and Stephen Taylor (now at Dartmouth), I designed the architecture and software systems for the DADO parallel computer, an example "Fifth Generation Computer" sponsored by DARPA's high performance parallel computing initiative in the mid-1980's. The DADO research group designed and built in my lab at Columbia University a fully functional a 1023-processor version of the machine that was the first parallel machine providing large-scale commercial speech recognition services (see announcement). The primary special purpose function of DADO was “pattern-directed inference” in large datasets. The speech recognition problem was among the best use cases demonstrating DADO. The DADO occupied about 2 cubic feet of cabinet space, perfect for an environment demanding a small footprint, like a Navy submarine. The DADO was tested at sea in a Navy research vessel to test its capabilities for related hydrophone acoustic analyses and detection capabilities. A parallel broadcast, match and resolve/report function introduced by the DADO machine apparently influenced part of the design of the IBM Blue Gene parallel computer. DADO’s Single Program Multiple Data (SPMD) model of Broadcast/Match/Resolve/Report invented in the early 1980’s is precisely broadly available in Apache Hadoop and Google MapReduce programing frameworks and systems. This connection is not widely known.
The DADO technology was the first invention claimed by Columbia University for ownership of a faculty member's intellectual property under the 1980 Bayh-Dole Act.
A company called Fifth Generation Computer was formed by Columbia and outside investors to commercialize the DADO machine. The company subsequently developed a commercially deployed speech recognition system operated by Qwest. Sometimes important inventions create adversarial relationships. Unfortunately, a dispute between the small company and a large telecommunications provider and Columbia University caused a six year detour into the US court system where ultimately I prevailed and "the parties resolved the dispute that was the subject of the litigation". I often advise young faculty to avoid complex business relationships that are not well managed by all the parties. Six years of litigation is not a productive use of a young faculty member's time and effort, especially when little to no support, financial or otherwise, was provided by any of the parties who created the confrontation and originated the disputes. Thank goodness I had managed to achieve tenure by that time, was the lone survivor of the “slaughter of the lambs.” (see page 191, https://cup.columbia.edu/book/a-lever-long-enough/9780231166881) When I retire (if ever), I promise to complete a book that will explain the details of the original landmines, explain how to avoid irrational confrontation between management of companies and university adminstrators, especially Department Chairs, and hopefully show how a pathway from chaos to success can be achieved even in the dauting pressures of academic politics and very strong personalities.)
Student Russell Mills (deceased, sadly) nearly finished his PhD thesis on ||C, an elegant parallel programming language based upon the C programming language. ||C provided an easy means of specifying MapReduce computations. Everything Russell did was elegant. (I defended his thesis and his degree was awarded posthumously.)
While DADO was built as a special purpose device, speech processing was one of the demonstrable applications at that time. Speech processing in general was an interesting problem studied by many in computer science. Student Nathaniel Polish,now at Daedalus Technology Group, independently studied and devised an automatic means of mixing language and speech elements to optimize the quality of sound of text-to-speech systems.
5. PARULLEL: PARALLEL RULE PROCESSING
Early work in deductive databases, as represented by early systems such as ACE, required scaling inference processes to large distributed data sets, and maintaining the logical consistency of the distributed inference process. Student Hasan Dewan and colleague Ori Wolfson (now at the University of Chicago) invented a number of algorithms to execute parallel rule evaluation against distributed data sets. In this work, the copy-and-constrain algorithm studied by student Alexander Pasik (deceased) provided a formal means of efficiently partitioning data and allocating rule processing to balance the load across distributed sites. This was truly the age where AI computations on parallel computing had enormous potential, but unfortunately insufficient depth in solving challenging problems. That would have to wait another decade or so.
Two students, Jason Glazier, and David Ohsie, each pursued somewhat independent lines of work. Jason developed a clever way of improving upon Monte Carlo simulations, so useful in many financial applications. David, on the other hand, initially worked on rule based systems and then developed a cool means of processing and correlating events in large-scale systems, especially useful in network management.
6. DATA MINING-BASED INTRUSION DETECTION SYSTEMS
While studying and developing algorithms for credit card fraud at Citibank, I was very interested in the concept of learning malicious activities from large amount of data generated by users of some system. I had a desire to develop algorithms and systems for fraud and computer intrusion detection. I briefed DARPA to pitch the idea of “behavior-based” security.
One of my sayings to students and colleagues is “let the data speak the truth”.
This was a time when computer security and intrusion detection in particular was based upon “expert knowledge”. Detection was based upon studying clever adversary attacks and coding “rules” to detect tell tale signs of those attacks. My view was to focus on applying machine learning to derive general knowledge to detect known attacks and variants not yet seen in the wild. Behavior-based security was an idea to learn “normal” behavior in order to detect abnormal behavior. This concept was not particularly new, but the application of modern machine learning to automate the process was entirely new to the field of security at that time.
After approving of my idea with substantial funding from DARPA's Cyber Panel program, I established the Intrusion Detection system (IDS) lab in 1996 and pioneered the use of data analysis and machine learning techniques for the adaptive generation of novel sensors and anomaly detectors.. One of the papers co-authored with student Wenke Lee (now at Georgia Tech) has been identified as one of the most influential papers of the IEEE Security and Privacy Symposium over the last 30 years. Another paper won runner-up best paper award at the SIG KDD conference. To date this line of work has been cited and referenced by many hundreds of researchers with thousands of citations. The key conceptions presented in Wenke’s thesis will be familiar to many today, applying “data mining” algorithms, frequent itemsets and associative rule mining, to network packet data to extract “features”. These features were extracted from the packet data to form “connection records” to which supervised machine learning algorithms would learn generalized “rules” to detect attacks. Hence, and IDS would be automatically learned with minimal guidance by a human expert. The approach has been replicated by many security researchers over the years. One of the important outcomes of this line of work was to produce for the first time realistic data for use by the research community.
7. KDD CUP DATA SET
The DARPA IDS evaluation datasets were constructed by MIT Lincoln Labs in 1998 and 1999 for the DARPA Cyber Panel program. These evaluations were largely due to my insistence on challenging researchers to present their work with formal statistical evaluations, the standard “confusion matrix” to reveal the accuracy of their specific intrusion detection systems. The MIT Lincoln Labs network trace data sets were constructed under DARPA support and used to evaluate the performance of different intrusion detection systems; they were the only network trace data with ground truth available to the open research community. The data, however, were difficult to use directly by a wider community of data mining researchers so the IDS lab including Wenke Lee created the KDD Cup dataset derived from the DARPA IDS datasets. The DARPA network trace data were converted to "connection records" making the data more suitable for data mining researchers to test various machine learning algorithms. This data created as a community service is extensively used in IDS research, even today, although that is unwise since that old dataset does not reflect more modern services and packet traces common today.
8. EMAIL MINING TOOLKIT (EMT)
The EMT system sponsored by DARPA contracts was among the first machine learning system to incorporate social network analyses in important security problems, including spam detection and virus propagation. The extensive set of analyses in EMT, developed in the IDS Lab by student Shlomo Hershkop (now at Allure Security Technology) and others, allowed analysts, forensics experts, students and researchers the opportunity to explore large corpora of email messages and discover a wide range of important derivative knowledge about the communication dynamics of a user or an organization. Among its applications, EMT models user behavior to identify uncharacteristic email flows indicative of spam bots and viral propagations.
One very interesting use of EMT was the inference of “important organizational hierarchies” in large enterprises.
Along with student German Creamer (now at Stevens Institute), we posited a simple but powerful heuristic corroborated by EMT analysis of the Enron datasets. The “average response rate” of a user, the average time someone responds to their message, identifies their importance in a social hierarchy.
The EMT toolkit had been downloaded by well over a 100 users and elements of the analyses introduced by EMT serve as a model for other analytical systems. The entire body of analyses demonstrated a general description of all IDS network and communication analysis systems conveniently described by the acronym, CV5.

Email Mining extracts user behavior information and knowledge of the social organization of an enterprise. Even viral propagations through email can be automatically detected.
9. CV5
I coined the term CV5, meaning Correlation of Violations of Volume, Velocity, Values and Vertices to serve as a general model of how IDS and network analysis systems operate. Nearly all IDS papers propose one or another method of detecting malicious events, and each of these can be described by the CV5 framework. Features are extracted from temporal streams of network, host, user, or communication data and that are modeled to identify anomalies or suspicious events. The statistical features that are modeled are volume (amounts of data, or number of events) and velocity (rates or speed), values (content of messages, or network packets datagrams), or vertices (connectivity of endpoints when participants in communication are considered nodes in a graph). The term "violations" refers to an unexpected value of the computed model of the system. When a sufficient number of violations are correlated (across sensors, across sites, or across layers of a system) an IDS will typically alert. My course on Intrusion and Anomaly Detection Systems taught at Columbia University explores the many different audit sources, features, and IDS systems that are each described as a specific instance of the CV5 framework.

The CV5 framework as a general model of an IDS system.
10. ANOMALY DETECTION: ALGORITHMS, SENSORS, AND SYSTEMS, PAYL, ANAGRAM, SPECTROGRAM
A number of anomaly detection algorithms have been invented in the IDS lab with students Eleazar Eskin (now at UCLA), Ke Wang (now at Google somewhere unknown to me), Janak Parekh (also at Google), Yingbo Song (now at BAE) and Gabriela Cretu-Ciocarlie (now at SRI), and have been deployed in commercial products licensed by Columbia University. Eleazar’s work introducing probabilistic anomaly detection algorithms lasted as the core of our work on anomaly detection for quite some time. Some of the mature content-based anomaly detectors, Payl and Anagram, have been deployed by the government in critical systems. Payl has been directly licensed and is in use in certain products.
The paper published on Payl recently won the RAID Most Influential Paper Award.
Among the earliest work in the IDS lab, Eleazar Eskin devised a general unsupervised anomaly detection algorithm based upon probabilistic framework as well as a geometric, clustering based framework. These algorithms are broadly cited and used in a variety of detection systems.
At the time a great deal of “signature based” IDS technology was widely deployed, but failing to stem the time of attacks in the wild. Anomaly Detection was a crucial technology in the security arsenal, but lacked sufficient practical and operational deployments. Our intuition was simple, malware and attack vectors are primarily delivered as data, malicious content delivering shell code to inject into a vulnerable application or service. Hence, detecting abnormal content was a key to detecting suspicious and perhaps malicious content. A great deal of work in the IDS lab focused on making content based AD systems practical and easy to deploy and use, and to essentially debunk the "folk-theorem" that AD systems generate too many false positives to be useful.
11. POLYMORPHIC ENGINES
One important contribution was work with student Yingbo Song on showing the inevitable demise of signature based approaches. The advanced polymorphic engines used by attackers to create arbitrary numbers of attack vector variants essentially rendered signatures impossible to manage. The quantitative analysis essentially established that Anomaly Detection was a necessary component for securing systems since each of these variants would manifest as abnormal content. Yingbo also implemented a sophisticated polymorphic engine called Hydra that generated arbitrary shell codes including a “time lock” that released the malcode at a prescribed time making reverse engineering difficult to achieve.

DATA MINING-BASED INTRUSION DETECTION SYSTEMS
12. STAND AND ADVERSARIAL MACHINE LEARNING
Security software itself adds to the attack surface of system in which it is deployed. There are a myriad of ways attackers can attack a system including disabling its defenses. One clever pathway, we conjectured, would be to poison a machine learning system to learn the attacks of an adversary were actually “normal”. Hence, cleaning the training data of an Anomaly Detection system was a crucial research problem.
The bulk of this work is reported in Cretu's thesis describing a system called STAND to limit the ability of advanced adversaries to poison the AD training data, and thus to implement mimicry attack to blind the AD sensors.
This area is now intensely studied as Adversarial Machine Learning. Stand was an early example of one way of approaching the problem.
13. WORMINATOR
I was an early proponent of collaborative security and distributed IDS technology and systems. I tried mightily but failed to convince the FS-ISAC folks to sponsor our work to demonstrate the utility of privacy-preserving sharing of detected network attach data, a common practice today offered by all of the AV vendors. Along with students Ke Wang and Janak Parehk we developed a fully functional IDS alert exchange system that introduced a new means of sharing sensitive data in a privacy-preserving manner.
The technique involved communicating network packet content found to be anomalous or verified as an attack after converting the raw packet content into a statistical representation allowing accurate correlation of common attacks across sites.
The method shares and correlates content across administrative domains without disclosing sensitive information with the use of Bloom filters storing n-gram content of network packet datagrams. The method was extensively studied and continues to be used in several ongoing experiments. The method also formed the basis of a recent project with colleagues Steve Bellovin and Tal Malkin for the secure querying of encrypted document databases without requiring the insecure decryption of any document when searching for relevant content.
14. BARTER – NETWORK ACCESS CONTROL USING MODELS OF BEHAVIOR
Many approaches to authentication and access control have been studied and deployed based upon user identities and associated authorized credentials. Credential theft, however, is common and unavoidable.
We had the bright idea that behavior can be extended not only to User Behavior to control access to endpoints, but device and node behavior can mediate access to networks.
Students Gabriela Cretu (now at SRI) and Vanessa Frias-Martinez (now at University of Maryland) developed an idea I had to allow devices to connect to mobile networks only by exchanging models of their behavior. A group of existing nodes would decide whether to admit the new unknown node into the network, if the model exchanged was deemed “normal”. The exchanged model announcing how the node behaves would also be continuously checked to ensure the device did not lie. Barter, as the network protocol was called, was later developed into modeling of users’ behavior in urban settings. I still believe this line of thinking has merit, but as yet hasn’t been fully realized.
15. PRIVACY-PRESERVING NETWORK TRACE DATA
Many security problems cannot be studied without data.
Security researchers in academia are hamstrung without large amounts of real-world data and often times their university network data has little to no analog in real-world network operations.
DHS sponsored a site called Predict.org to allow industry and research partners to share real network data, but under very tight constraints of access. Even so, much of the data provided remained devoid of critical content due to legitimate privacy concerns. Full packet capture including datagrams might reveal corporate secrets, or personally identifying information about customers. Yingbo Song (now at BAE) developed an excellent approach to learn the statistical characteristics and properties of a real network trace, and then to use these models to automatically generated entirely bogus and but realistic synthetic data that could be freely used among researchers to study various security solutions. Automatic generation of synthetic data is now commonplace.
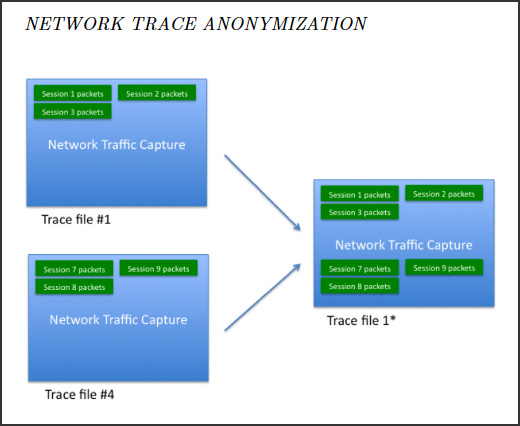
Automatic k-anonymity privacy-preserving network traffic generation by mixing network traffic.
16. SPARSE: STATISTICAL PARSING OF DOCUMENT CONTENT
Just a few years ago most users felt entirely safe in exchanging Adobe PDF documents in emails and file shares. Other common file formats are often considered dangerous and are typically filtered by email service providers since they may harbor malware. Malware-laden documents are pervasive on the internet today. With student Wei-Jen Li we created a system that parses the binary format of Word documents and extracts and models statistical features based on n-gram analysis of the large number of object types embedded in Word documents. The resultant system was tested by a red team and demonstrated a number of techniques to identify suspicious documents, and prevent malware exploitation.
17. APPLICATION COMMUNITIES
Along with colleague Angelos Keromytis (now on loan to DARPA) and other colleagues at Columbia we proposed the concept of "Application Communities" and assisted DARPA in running a workshop on that topic that ultimately led to the DARPA research program of the same name.
The technology concept involves profitably using a monoculture of an application (a large number of endpoints running that application) as a "security sensor grid" to improve the security of all community members.
The method and system is designed to rapidly generate a patch and update all hosts when an attack is identified and validated by the initial victims, a small set of members of the application community. These kinds of processes are now commonplace by most application vendors.
Indeed, one such vendor has employed the technology since 2009, but alas without a license from Columbia University. A lawsuit was filed by Columbia that ultimately led to a jury trial finding the NortonLifeLock willfully infringed the patent filed on this work.
18. THE INSIDER THREAT: RUU?
The insider threat remains the most vexing of all security problems. In 2005 I received funding from ARO to conduct a workshop to bring together a group of researchers to help identify a research program to focus on this important topic. Since then the IDS group at Columbia working with other researchers at the I3P developed several demonstration systems evidence of insider malfeasance. The work includes user profiling techniques (especially for masquerader detection. "RUU" is a spoken acronym for Are You You?) studied with student Malek Ben Salem (now at Accenture), and a number of decoy generation facilities studied jointly with co-PI Angelos Keromytis and student Brian Bowen (now at Sandia). A recent paper on the RUU project won best paper award.
The effort has developed a number of interesting publicly available datasets for user studies, and novel "advanced behavioral sensors", including a decoy generator system, accessible through a public website, that produces decoy documents with embedded beacons and a relatively well developed theory of describing and measuring the properties of a decoy to guide the generation system.


19. SYMBIOTE AND IoT SECURITY
Student Ang Cui working in the IDS lab co-invented a concept to embed arbitrary code into legacy embedded devices. The symbiotic embedded machine technology has been demonstrated to provide a direct means to inject security features into operational CISCO IOS routers in situ without any significant performance degradation and without any negative impact on the router's primary function.
This line of work was supported by the DARPA CRASH program that has brought together a very large number of computer science researchers focused on clean slate design for a new generation of safe and secure computer systems.
The Symbiote technology was named one of Popular Science’s “9 most important security innovations of the year” . Preliminary work performed by student Cui in the IDS lab performed a wide area scan of the internet counting the number of vulnerable devices. To date over 1.1 million have been found. The results were recently published and won best paper award. And a great deal of media attention.
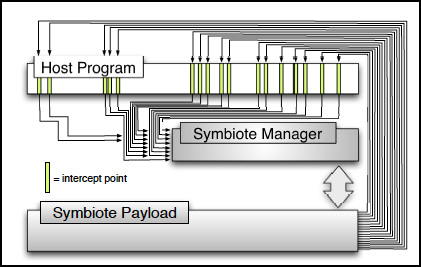
Symbiote technology for injecting IDS functionality in arbitrary embedded and IoT devices.
20. HARDWARE AND DEVICE SECURITY
Collaborator Simha Sethumadhavan and student Adrian Tang in the IDS Lab had a particularly neat idea to challenge modern architectural designs of widely used ARM chipsets. With Simha he developed a means of attacking and manipulating the energy management software of a modern ARM processor to force it to reveal the protected keys in the ARM Trust Zone. A clever and amazing accomplishment earning the most distinguished paper award at Usenix Security 2017 and was selected as one of the winners of the IEEE Micro Top Picks 2018 award.

21. SELF-MONITORING MONITORS FOR SECURITY IoT
I wondered whether there was any work on methods to protect a system to prevent it from purposefully engaged. Collaborator Steve Bellovin pointed me to a couple of papers on Sandia’s website describing the history of nuclear weapon designs.
The stronglink technology was devised by physicists to automatically generate a “key” to enable the device to be fired. I was looking for a technique to disable the turning off of a device. The duality is obvious.
Student Yuan Kang (Google) has studied this concept I proposed some time ago but never published, the notion that defenses should be self-defending. It is commonly seen that malware will disable endpoint protection software before executing their goals and mission. Hence, security software itself is subject to attack. Yuan’s work extended the idea to self-monitoring monitors, a security architecture composed of randomly connected monitors that each protect some application or device, and monitor each other in the case any component monitor is shut down.

Randomly generated graph of self-monitoring monitors to protect a security system, based upon stronglink concept that secures from inadvertent discharge of nuclear weapons.
22. DECEPTION SECURITY: DECOYS AND FOG COMPUTING
FOG Computing involves systems and deployment strategies that create and plant believable bait and decoy information in storage systems in the Cloud and network traffic in a manner that causes no negative impact on operational systems. Our proposed approach is to confuse and confound an attacker by leveraging uncertainty, to reduce the knowledge they ordinarily have of the systems and data they now gain access to without authorization. FOG computing systems integrate bait information with systems that generate alerts when a decoy is misused.
We believe our work to be the first to systematically propose the study and creation of bait information of a wide variety of types with the aim of thwarting (or at least exposing) the exploitation of exfiltrated information. Much of this line of work was driven by the Insider Threat problem, but as well to provide a solution to the general problem of data loss.
Oddly enough, the paper on FOG has been widely cited by a number of researchers who apparently have confused the term with “edge” computing in ioT and cloud environments.

Deception Security and decoys can be applied to a very wide range of media, types and networks protocols and traffic.
23. SCIENCE OF SECURITY AND SECURITY METRICS
Security is a property of a system not well defined. Typically the term is defined by other properties, such as availability, confidentiality and integrity, in turn properties that are not well defined. However, I posit that there are a number of techniques to measure the relative security of systems; it may be possible to determine one security architecture design is better than another since one may detect a wider range of attacks than another. This approach requires the means of measuring the security posture of systems.
Student Jill Jermyn (now with Google) in collaboration with researchers at Berkeley’s ICSI developed a means of testing online systems that filter content. Her work accomplished the means of measuring and revealing the “rules” of censorship filters on the internet to identify their behavior and learn how to evade their filtering.
Student Nathaniel Boggs approached the problem by developing tools to automate the process of testing security systems in a defense-in-depth architecture. The key to proper testing is to identify a set of realistic attacks, and integrating the information each detector focuses on in its decision process. This information allows a detailed evaluation of an architecture of specific detectors to determine if any individual detector provides added coverage, or not.
One of the burning questions I am pursuing along this line of thought is whether one can architect a defense-in-depth security system where layers of defenses are designed to force a multiplicative cost to the adversary rather than a linear cost common today. This is a hard challenge problem that might be approachable.

A simple view of the desired goals of architecting a security system to increase the cost of an adversary to penetrate defenses.
24. SIMULATED USER BOTS (SUBs)
In measuring Insider Threat detection systems, little is known about how well a particular deployment works. Recent work in the IDS lab led by student Preetam Dutta and grad student Gabriel Ryan, focuses on Simulated User Bots (SUBs). A SUB might be construed as a “decoy user”, an automated endpoint user placed within an enterprise network, and which operates as a real user. The behavior of the SUB under controlled conditions can measure the accuracy of a deployed insider threat system simply by having the SUB misbehave!

A plot of one feature measured for different users showing high variance and hence individual behavior varies greatly. Generating a model of an “average” user is quite hard.